

Datapoints, Label Encoding XBRL and AI?
Why abstract encoding of labels does not help AI understand XBRL data, nor humans.
An article on Medium about why encoding data labels can introduce challenges for AI systems inspired this post. The notion that abstract encoding is bad for Large Language Models (LLMs), led to the thought that encoding must be unhelpful for human understanding for similar reasons.
While generating encoded labels is essential for various IT applications, it introduces special challenges for how XBRL collection systems operate, such as the European Banking Authority’s (EBA) reporting framework. The EBA uses both Data Point Methodology (DPM) and eXtensible Business Reporting Language (XBRL) in the implementation of its Credit Risk Directive (CRD) system.
The EBA generates the XBRL taxonomy from its internal DPM model and provides it to 27 European country authorities that collect the XBRL reports from thousands of banks. The move to a new, more compressed, collection format, XBRL-CSV, is an opportunity to consider how the XBRL model is generated and how it is understood by the banks that are required to report in the format. It is also a good time to review how the XBRL data is analysed to help the supervision of banks in Europe.
This article tries to evaluate the impact of the DPM encoding in the XBRL taxonomy and how it affects the communication of the reporting requirements, i.e., does it cause significant additional effort to implement and maintain the collection and reporting systems? It also reviews if DPM encoding also acts as a barrier to using advanced AI tools in the future to discover potentially useful information in the large datasets being collected.
Encoding the DPM Approach
First, we need to explain how the EBA’s approach to DPM and XBRL works. It starts with the analysis of spreadsheets defined by the business experts to identify the data that needs to be collected. Each sheet is viewed as a Table and given a Table name, e.g., ‘F.02.00’ which is the ‘Statement of profit or loss’ in the FINREP module. In the sheet, each data point is provided a dynamic code based upon the column and row. For example, the coordinates ‘F02.00, c010, r670’ is the datapoint at row 670, in column 10 in the FINREP table ’02.00’, which is labelled ‘Profit or (-) loss for the year’ and the ‘Current Period’ for the column.
The next step in the EBA’s DPM approach is to analyse the datapoints using a highly dimensional approach, so in the resulting model there are very few metrics (‘concepts’ in XBRL), but numerous dimensions to break down the data into the individual data points. The DPM model is then used to generate the XBRL taxonomy. How the model is generated has a major impact on how people in the collection process understand it.
The current approach leads to an EBA CRD taxonomy that is extremely hard to review using XBRL tools because of the highly dimensional structure and the use of DPM encoding. If you look inside the EBA’s CRD taxonomy which provides the core dictionary, structure, and validation rules, it is difficult to discern any semantic structure. Effectively, the DPM encoding, and use of extreme dimensionality has stripped all the semantic information away.
XBRL Taxonomies are typically designed to be self-explanatory and self-contained to provide all information needed by the reporting entity. However, the EBA feels the need to publish a set of associated non-XBRL documents, including annotated templates in Excel. The latter provides the user with the necessary Table layouts to understand what needs to be reported and how the data is linked to the Taxonomy.
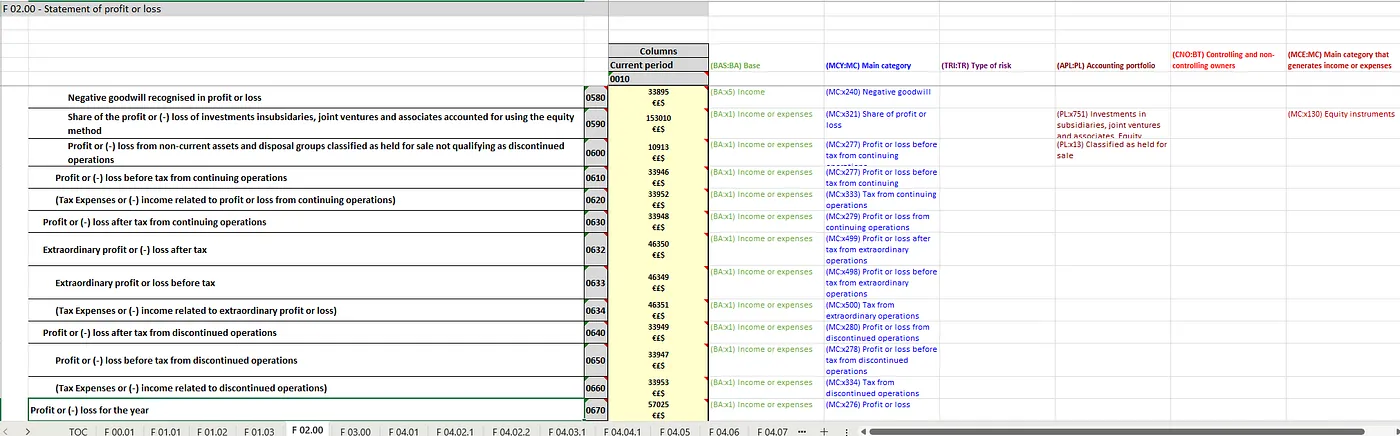
The FINREP F02.00 annotated template describes semantically the item to be reported. It also provides the DPM coordinates for column and row in the grey cells. Each datapoint is given a datapoint id (DPM-ID) highlighted in yellow. Finally, on the right-hand side are the list of dimensions for each datapoint In the XBRL CRD taxonomy.
In XBRL, the structure of a table is defined in a Table Linkbase. These definitions enable software developers like UBPartner to derive the ‘mapped’ Excel templates. The semantic label ‘Profit or (-) loss for the year’ is not provided anywhere else in the taxonomy and it is not defined directly but encoded (…of course) as ‘label_eba_c70878’ and points to a label definition in the Label Linkbase. (Ed: I hope you are keeping up?).
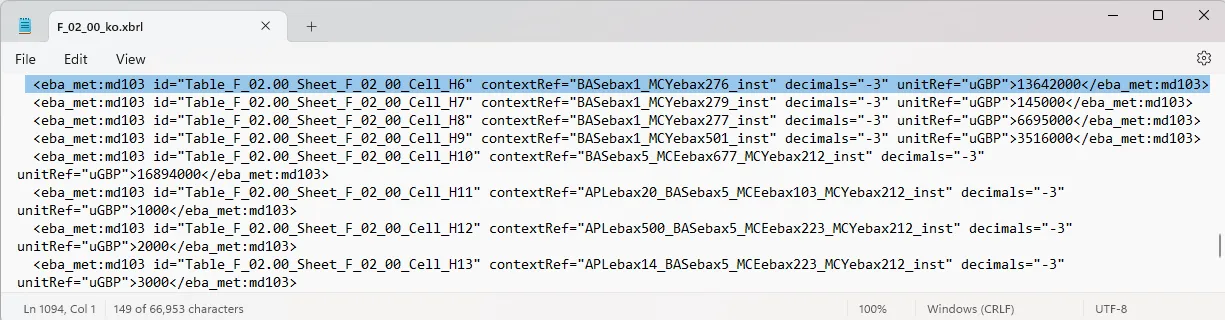
The generated XBRL instance document (data file) shows the level of abstraction. There is no reference or semantic encoding of the above profit or loss label, just one concept ‘eba_met:md103’ for ‘current period’ (which is unusual, more later) and context references which link to the dimensions. (Note: The id references in the file are defined by UBPartner using the cell reference to help to debug the system as even our XBRL experts need them).
So, the current ‘mechanical’ translation of the DPM model to the EBA CRD collection system is only understandable for humans if you have the associated EBA documentation, and particularly the annotated templates. Not really in keeping with the typical approach for XBRL.
Moving to XBRL-CSV Reporting
From 2025, the EBA intends to use a new format to compress the data and reduce the file sizes of reports. The new format is XBRL-CSV, which we reviewed in an earlier post (see more here).
The EBA plans to use the DPM-ID code, such as ‘57025’ from above, as the key identifier in the new XBRL-CSV format. It is then linked from the CSV file to the XBRL Taxonomy via a JSON metadata file, which describes the layout and meaning of the CSV elements. So, the ‘Statement of the Profit or Loss’ table in XBRL-CSV will look something like this:
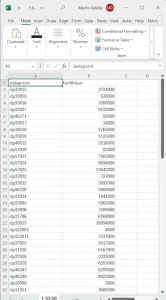
The DPM-ID is a pure database construct, a code to act as a simple database key to describe one of these data points. It has no semantic value and is pure abstract encoding, containing no grouping information to help processors optimise performance. DPM coordinates can be thought of as first level abstractions or encoding. The DPM-ID a second level abstraction
In Harrison Hoffman’s article ‘Categorical Features: What’s Wrong with Label Encoding? Why we cannot arbitrarily encode categorical features,’ published on Medium, he argues that encoding labels adds nothing to Large Learning Models, as used in ChatGPT, etc., as encoding loses ‘context and nuance’ by simplifying complex attributes or classifications into abstract or numerical representations. This results in the poor performance of AI systems used to explore the data.
Based upon similar arguments as Harrison Hoffman’s, we believe that the level of encoding used in the EBA XBRL taxonomy and using the DPM-ID as the key identifier in the proposed XBRL-CSV structure, makes it more difficult to apply Machine Learning to these large datasets, hence harder to ‘discover’ new relationships in the data using advanced AI tools.
So, highly encoded systems like the EBA’s CRD reporting framework affect both understanding by humans and AI, but why the fuss many IT systems are built like this?
Discover how we can help you meet the challenges of XBRL reporting
Contact our sales team to book a demo and discuss your XBRL challenges
Encoding the Human Impact
The EBA CRD reporting framework collects complex information related to banks performance and operation, where each bank has their own heterogeneous data systems and processes to collect the required data. XBRL should function as the lingua-franca to help the thousands of banks determine what they need to report. XBRL’s ability to standardise the data dictionary and validate reports is why it has been so successful for regulatory reporting systems, where data quality is essential.
However, in contrast to the EBA CRD taxonomy, XBRL taxonomies, such as the widely referenced IFRS taxonomy, uses concept labels which are semantically rich, such as ‘profit’ and ‘loss’. It uses the Presentation Linkbase to show the user the hierarchy of concepts, uses the Calculation Linkbase to show simple mathematical relationships, and uses short, natural language names for dimensional breakdowns, e.g., ‘net operating profit’ and ‘profit before tax’.
It is obvious that encoding labels in a collection framework can lead to ‘interpretation challenges’ which can lead to misunderstandings. The EBA publishes and keeps in-sync a range of non-XBRL documentation, such as the annotated templates, it calls the Implementing Technical Standards (ITS) on supervisory reporting to support the framework, which is both time-consuming and expensive. Could the EBA have avoided much of this additional work if the Taxonomy had been modelled differently?
In this environment, if a report fails validation, such as when an XBRL Formula produces a strange result, the analyst often needs to consult many of these non-XBRL documents due to the opaqueness of the XBRL model, i.e., encoded concepts and dimensions, causes the analyst additional work. So, the EBA’s approach is effectively passing costs along the information supply chain to the 27 European National Competent Authorities (NCAs) who manage the local XBRL reporting framework and the banks that are mandated to report.
It is hard to measure the wasted time resolving the abstractions caused by encoding but the move to XBRL-CSV and the use of the DPM-ID is expected to create additional work with the addition of yet another level of indirection in the reporting process. Software, of course, will be able to read the JSON descriptions provided as part of XBRL-CSV, but bank compliance officers and analysts will be reliant on reading the annotated templates to understand the meaning of each DPM-ID by translating from the sheet, row, and column ids. While debugging issues will require to resolve all the levels of abstraction in the Taxonomy via the JSON metadata. As now, XBRL software vendors will be required to continue to deliver rendered spreadsheet templates or alternative simpler CSV formats as input options.
Encoding the Analysis Impact
So as a communication of the CRD reporting requirements, the current XBRL Taxonomy is not great, but is the proposed move to XBRL-CSV format using the DPM-ID as the key identifier worse? Alternatively, is the additional level of abstraction offset by the approach’s ability to deliver the objectives of the system, i.e. to supervise the banking market in Europe, better than before.
The DPM approach, for sure, has helped the EBA to derive a consistent model and data dictionary across the banking system. The datapoint approach works well for systems that produce pre-determined analysis, such as OLAP and traditional Data Warehouses.
It is assumed that both the EBA and NCAs use the large dataset of European banking information to derive a set of key bank performance indicators against which to compare individual banks. Historic trend reports and various dashboards are also easy to produce. However, one suspects that much of the collected data lies unused for bank supervision as such reports are limited to what humans can cope with, i.e. highly aggregated data or where there is a need to analyse in more detail a specific dataset where a warning has been raised.
The power of AI analysis is that it could help find potential hidden nuggets of information in the volumes of detailed data. However, as Harrison Hoffman’s article argues the use of DPM encoding in the collection system does not help the use of LLMs on the resulting dataset. Machine Learning could be used on the raw datapoint data, but the AI system would have to be extensively trained in the DPM approach and architecture, and how the DPM-ID is linked to meaningful labels. This would all be at additional cost and need extensive expertise.
LLMs and modern AI techniques work in a different way to standard data warehousing and traditional AI (supervised learning), i.e., via unsupervised training of models, sometimes augmented by additional specific knowledge, retrieval-augmented generation (RAG). At scale, special things begin to happen as with language models, such as, GPT, Llama and Gemini, where they begin to display general language understanding. This type of AI approach would be simpler and cheaper to apply as the technology matures. So, will the EBA be missing out from future-proofing its systems architecture?
Modern database architectures, such as semantic databases, enable the efficient collection of XBRL data and there are cheaper, simpler SQL based XBRL databases for smaller applications. These technologies can provide an operational data store on which to run the type of discovery algorithms that AI is good at. Given XBRL’s inherent structure, it is also easy to transform and load (or load and transform) to analytic structures, such as a DPM database.
So why is the EBA intending to promote the DPM-ID from a hidden abstract database label to centre-stage in the information exchange? Is it just because it fits their internal analysis database structure?
Encoding Alternatives
We believe that XBRL-CSV is a perfect fit for the EBA upgrade of the CRD reporting framework as it can significantly reduce file sizes of submitted reports. This is why the XBRL Standards Board (XSB) built the Open Information Model (OIM) specification which defines both XBRL-CSV and XBRL-Json. The concern is that the EBA is using it incorrectly in terms of the XBRL-CSV structure. For the first time, the EBA is planning to introduce the DPM encoding directly into the XBRL reporting using a semantically vacant construct, the DPM-ID as another layer of abstraction.
Without repeating the arguments in the original paper, we believe that the new XBRL-CSV structure based upon the DPM-ID will make it more difficult for both humans and AI to understand. On the positive side, the files will be smaller and at least for the EBA, it will find it easier to load the collected data to their own DPM database. However, there are 27 NCAs and thousands of banks to consider when assessing the impact.
The alternative would be to just use good XBRL modelling in the first place. However, the redesign of the DPM tools to produce a ‘better’ semantic XBRL model would be a significant effort and cost, plus raise other issues. For example, the issue of verbose XBRL terms is a real one. Encoding ensures a fixed size for naming elements, whereas in a typical XBRL model the concept and dimension names are of variable length. The latter means that any XBRL system can be verbose and generate large files depending upon the application. However, the XBRL specification does allow for both short and long labels, so we believe that such issues can be addressed by ‘simple,’ non-abstract encoding.
As an alternative, the EBA could use the Table layouts (grid approach) in their XBRL-CSV model.

It is easier for humans to visualise the table layout and it would help software vendors, which already render the Table Linkbases in other forms, such as spreadsheets for input purposes and render useful error messages to business users. However, this would require a greater level of transformation by the EBA when loading their internal DPM database.
One compromise could be to use the DPM coordinates as dimensional identifiers in the XBRL-CSV. Banks understand the coordinates from the annotated templates — a simple visual abstraction. if the DPM coordinates were used in the XBRL-CSV file format instead of the DPM-ID, it would also enable XBRL processors to identify groups of data, i.e. all the data in a column or row, a relationship between the data to be used to improve processing speeds. By simply reversing the roles the EBA could help users understand the data and still make it easy to load into their database, i.e., use the DPM coordinates, sheet, col, row ids in the CSV structure and link these to the DPM-ID in the technical JSON metadata.
The EBA would argue that the DPM-ID has historical robustness which the spreadsheet coordinates do not have, as the spreadsheets change between reporting periods. However, XBRL Taxonomies are updated every reporting period and so are transitory by nature. Hence, using the DPM coordinates for a Taxonomy does not impact the analysis system, simply the transformation and loading of data. Plus, the EBA already has the historical connection between the datapoints via the DPM-ID in their internal analytical database, which is where the historical connection between reporting elements should be made.
Using the DPM coordinates would also link to the DPM notation for data quality checks. The proprietary notation is used to help construct and document XBRL formulas for checking the accuracy and consistency of the reported data. These rules take a significant effort to code and test. XBRL Europe is proposing an XF DPM format for writing EBA formulas that would work at the sheet level rather than datapoint. Making the rules simpler to write and easier to process. Eventually, if there is a semantic structure to the data model, AI techniques could be employed to produce these rules directly from the semantic model using the element structure and naming.
Once regulators and software vendors get the new format working, the XBRL-CSV collection system should work without issue, but… and a big but, like other collection systems based upon such proprietary data storage systems it may become stuck in time. In our experience, these kinds of systems are typically inflexible structures and dependent on technicians to resolve issues.
Conclusions
From our viewpoint, the EBA appears to be going in the ‘wrong’ direction as it moves to XBRL-CSV reporting, encoding everything, and throwing away the semantic richness contained in the business developed spreadsheets. The few benefits of the approach accrue to the EBA, but not to the NCAs or banks that collect or produce the reports.
Our key takeaway is that by adopting the DPM-ID as the key identifier in the XBRL-CSV structure, the EBA is both making it harder for humans to understand the structure and meaning of the data and may also be cutting themselves off from an important shift in computing towards AI based analysis of large datasets. As computers are ‘taught’ how to think like humans, they are looking for semantic relationships between data, such as meaningful semantic concept names, and structure based upon hierarchies and tables, that can ‘steer’ their understanding.
The authors are Kapil Verma, David Bell, and Martin DeVille of UBPartner
Please send comments, corrections, and any alternative ideas to info@ubpartner.com.