

Digital Financial Reporting and AI
Is Automatic XBRL Tagging Feasible Using AI and LLM systems.
Research by Patronus AI has highlighted apparent challenges faced by large language models (LLMs), such as OpenAI’s GPT-4, in analysing financial data contained in US Securities and Exchange Commission (SEC) filings. The study found that even with access to extensive filings, the best-performing model at the time, GPT-4-Turbo, achieved only a 79% accuracy rate. XBRL International (XII) was surprised to find (…and so were the authors of this article) that they had not used the XBRL data tags available for these reports in the analysis.
Further research by XBRL International (XII) showed that “AI systems like OpenAI’s GPT-4 demonstrate improved performance in answering financial queries when fed with structured xBRL-JSON files converted from the SEC’s 10K Inline XBRL reports”. Like XII, we find this an obvious result, i.e., that using the semantic tags provided by companies of their own financial data would produce better results and that structured data can provide significant benefits to financial disclosure analysis.
However, what if you reversed the process and ask AI and LLMs to tag a financial report with XBRL?
UBPartner has been undertaking some fundamental research on using natural language processing to identify key information in an annual report. Below is a summary of the initial UBPartner results, plus a look at what the latest developments in LLMs might offer to improve the performance, and an initial view on where this is heading. This is part of a series of articles looking into key issues around Digital Reporting using XBRL.
Rapidly Advancing AI Capability
Over the last few years, interest in Artificial Intelligence (AI) has developed quickly, in particular, the area of Large Language Models (LLMs) and general language generation tools has moved exponentially with the release of Open AI’s Chat GPT-4, March 2023. LLMs have quickly become the centre of attention due to their ability of producing humanlike text and code responses to natural language prompts in seconds. Applications have appeared across various domains, such as: conversational search agents, chatbots, text summarization, content generation, language translation, data analysis, and some are even using it to generate computer code.
Given this level of ‘language’ understanding, LLMs should also be able to be trained to help understand financial disclosures and potentially go further than just analyse and summarise, The ability to identify key pieces of information in large pieces of text suggests that LLMs could help to identify specific metrics, paragraphs, and sections in a financial report, such as those provided to the US SEC or to ESMA under the ESEF framework. This could then be used to tag the key information with XBRL.
Today, financial reports must be tagged manually by humans that need to understand both financial reports and XBRL. So, using AI would save a lot of effort and potentially tag data in a more consistent manner, especially when one considers that the next set of major XBRL reporting will be sustainability reports.
The Nature of Financial Reports
An Annual Financial Return is a document that describes not only a company’s financial position, but also its current and future strategy, and much more. Companies are required to provide such documents by law in most countries. So, what is Digital Financial Reporting?
“Digital financial reporting is financial reporting using structured, machine-readable form rather than traditional approaches to financial reporting which were paper-based or electronic versions of paper reports such as HTML, PDF, or a document from a word processor which is only readable by humans. A digital financial report is readable by both humans and by machine-based processes.” according to Digital Financial Reporting, Wikibooks.
Digital Financial reporting requires the identification of key elements of information both numerical and textual, then tagging them with standardised accounting concepts, typically either IFRS or local GAAP. Below are some common characteristics of these reports and frameworks:
- Numerical data is often organised in tables (core statements, like profit and loss or the balance sheet, or detailed data in a disclosure note) which have their own row-column structure. Most humans instinctively recognise the structure of Tables if not all the detail. Text is often organised in blocks, i.e., disclosure notes related to specific numbers, sets of numbers or tables.
- While the IFRS or local GAAP dictionary is standardised, each company selects the elements it reports in its annual financial return. A bank’s set of reported facts is very different to an industrial company.
- Each company, even within an industry, has its own context and specific terms and may have information that is specific to the company that may need to be disclosed.
- Accounting standard setters or market agencies have a list of standardised labels for concepts that are typically found in a financial report, which is continuously updated. Over the last 10-15 years these have been made available as part of an XBRL Taxonomy that provides a common dictionary with meta information on type of element, units, etc. It also includes the relationships between elements often via a hierarchical structure, i.e.’ we can see that ‘profit or loss’ is equal to ‘revenue’ minus ‘costs’; and that ‘revenue’ is the sum of a list of revenue line items, and so forth.
Discover how we can help you meet the challenges of XBRL reporting
Contact our sales team to book a demo and discuss your XBRL challenges
XBRL Tagging
XBRL is a standard for transmitting business data between computer systems in a standard format. This has proven extremely attractive to regulated reporting frameworks. There are now some 216 regulatory reporting frameworks that use XBRL worldwide.
Initially, XBRL was based only on the XML format. This format is ideal for complex data centric reporting, where typically the data can be rendered into defined Tables. But XML is not very human-readable, and an annual financial return would need to be accompanied by an associated HTML, PDF, or Word document for humans to review, leading to data duplication and inconsistencies. The Inline XBRL (iXBRL) format merges the machine-readable XBRL data with an HTML document, so it is both human-readable, while also enabling systems to extract and analyse the information that has been tagged.
Using a special inline XBRL viewer the reader can see the financial tags that the company has used, and hence can understand the ‘model’ behind the financial statements. Such tools can reveal what elements of the report have been tagged, the calculations between elements of the statement and further references to the relevant IFRS or GAAP guideline for the element. The critical element from both sender and receiver is that XBRL software can use these definitions to automatically validate the file, i.e., is the information provided as the right data type? do calculations add up? Is duplicated data consistent? etc. Taxonomy architects also have a rich rules language, XBRL Formula, with which to define other more complex types of rules to be checked, such as, does it contain the mandatory data.
Despite the availability of commercial tagging tools, embedding XBRL fragments within an HTML report needs a deep understanding of XBRL, the specific taxonomy hierarchy and the underlying accounting principles and practices. Most tools today therefore rely on a human to choose and apply the relevant tag to each item of data and text.
Some vendors do claim the use of AI tagging in their products. On closer inspection, most are simple fuzzy text mapping software that can make simple identification of words that are ‘similar’ to the taxonomy concepts. They can present well, but in real tagging usage produce many ‘false-positive’ matches. These ‘false positives’ take time to identify and fix, so the real benefit is highly questionable.
Other approaches exist for helping people tagging or reviewing reports, such as ‘expert categorisation’ of taxonomy elements can help make the mapping process more efficient by showing the person tagging the accounts which are the most obvious tags for the specific context. Such an ‘expert system’ is used in UBPartner’s XBRL mapping tools but does not deliver automation.
Auditing the use of XBRL tags is critical for investors using digital financial reports and analysing the data. Clearly auditors benefit greatly from the standardisation and validation that XBRL brings to annual financial returns. An iXBRL Viewer is useful for reviewing individual documents but more powerful benchmarking tools require an XBRL database. However, even many of these systems cannot fully expose simple issues where the wrong tag has been used for an element in the specific context. Manual reviews of the list of tagged elements are time-consuming and costly.
However, what if AI and in particular machine learning (ML) and LLMs that have a good understanding of language, could be used to tag the core report with a degree of ‘trustworthiness’, so that humans just had to look at a few remaining ambiguous areas?
UBPartner has been exploring natural language processing (NLP) to see how it could help to automate the process of producing digital annual returns, thus reducing errors, and improving the readability for investors. It is very early days and there are some difficult issues to overcome, but the technology is improving fast.
AI Tagging Initial Evidence
UBPartner undertook research on AI XBRL tagging at the beginning of 2023 before ChatGPT 4 was released. The project used a more traditional Natural Language Processing (NLP) approach – a pipeline approach focussed on the specific tasks, offering fine-grained control and customization options. LLMs like GPT-4 are based on transformer architectures. These models are trained end-to-end on vast amounts of text data and learn to generate text based on the patterns and structures present in the training data and are better at general-purpose models capable of performing a wide range of NLP tasks.

NLP Pipeline Approach
At a high level, any Natural Language Processing pipeline can be divided into five distinct steps, as shown in the Figure below.
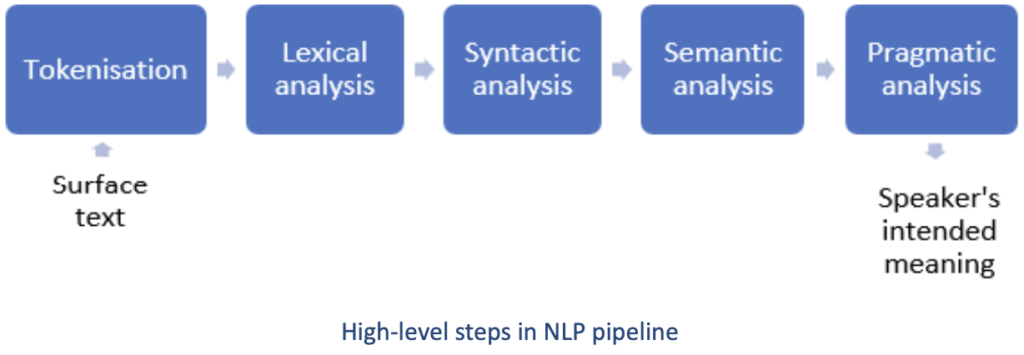
First the tokenisation step decodes and segments the input text into words and sentences. The tokens are then fed to lexical analysis where the words are linked to their lemma. This step links different variants of a word to the stem while also capturing the type of variations in a lexical model.
The syntactic analysis takes the lexical model and determines the sentence structure as per the formal grammar rules. It attaches POS symbols to the words in the sentence.
The syntactic model is fed to semantic analysis, where the words are attached to their meaning and relationships between the words are determined. The syntactic structure is further analysed to determine the meaning of the sentence in the context of the text (pragmatic or discourse analysis).
Pragmatic analysis enables meaningful comparison of two differently worded sentences with similar meaning, which is useful in find the correct XBRL concept by matching the labels in the taxonomy and the text from the XHTML report.
Initially, the UBPartner project used sample US SEC filings to test and train the approach. So, effectively it was looking at the same type of data as the Patronus AI paper.
The key research questions were:
- Can NLP identify relevant numbers and text in the financial statement that needs to be tagged?
- Can NLP identify the correct XBRL tags for the identified element in the XBRL taxonomy?
The expectation was that the NLP approach would provide better results than current string processing approaches used in some current XBRL tools. Hence, the approach calculated a score for both NLP and fuzzy text search to compare results. It is also measured factors to identify if NLP could provide performance characteristics required for these tools to operate in a production environment.
The proof-of-concept (PoC) used UBPartner’s XBRL Processing Engine (XPE), and libraries such as CoreNLP, HtmlUnit, and Bellsoft Liberica JDK, which are open source. For a specific company, the POC:
- Created mappings for the reported data sets from previous filings and from the XBRL element labels in the taxonomy.
- The mappings were then used to find the relevant HTML text and the tag that should be applied to the identified text.
- The taxonomy labels, extracted using XPE, were put through a CoreNLP pipeline to generate annotations, semantic graphs, and canonical definitions of the concepts (lemmas).
- After preparing the mapping data, the program sought to identify the XBRL tags for the table cells in the test data structure.
To start with the POC was restricted to the tabular data. The financial filings of an organisation for successive periods usually report on similar line items, hence it is expected that past filings would provide required knowledge to identify text and metadata in future documents.
The summary report below shows the percentage of correct and incorrect tags, and the tables that were wrongly tagged, for some of the more interesting samples.
The table shows that the PoC performance was very inconsistent (see Company C), however the POC did find 70 to 80% of the tags for most of the reports in the wider data set. The standard financial statements (like Balance Sheet, Cash Flow statements, Property Plant and Equipment etc) were tagged accurately.

A more detailed review showed that the algorithm fails mostly in the HTML analysis step, where table structures are too complicated or non-standard to process and generate the models and mappings. However, the NLP processing was found to consistently improve the number of tags found against string matching.
The performance of the program was between 10 to 100 seconds, which is acceptable for a user facing application, as the auto tagging process is expected to run once.
This model could be developed further to improve the above results and extended to focus on other sections, but there would always be new structures and terms it would find for the first time that would cause it issues. So, could the process of identifying tags be improved using LLM models?
Using LLMs for Tagging
From a Natural Language Processing viewpoint, the initial UBPartner POC results were no better than the Patronus AI research using ChatGPT. However, LLMs do not incorporate the knowledge contained in the XBRL semantic model of US GAAP or the IFRS taxonomy, the typical structure, and characteristics of Financial Disclosures, nor the XBRL tags in the previous reports used for training the UBPartner model. So how can these be built into the use of LLMs for tagging financial disclosures.
To fully understand the potential, it can help to understand how LLMs work in more detail and elements such as transformers, vectors, the concept of embeddings, retrieval augmentation, and context windows. The section below describes some of the important LLM concepts, but you can skip if you wish.
Large Language Model Architecture
Transformers are a specific type of neural network, and they underpin all today’s LLMs. They turn volumes of raw data into a compressed representation of its basic structure, using vectors. One central idea behind transformers is the concept of ‘attention’, which weighs the relevance of different contextual inputs, enabling the model to focus on the more important parts when predicting the output.
Embeddings are made by assigning each item from incoming data to a vector in a highly dimensional space. Since close vectors are similar by construction, embeddings can be used to find similar items or to understand the context or intent of the data.
LLMs can be inconsistent and are said to ‘hallucinate’, which is not a good characteristic for a financial disclosure markup tool. It happens when LLMs do not have enough information to generate an accurate response. Retrieval-augmented generation (RAG) is a method for improving the quality of LLMs responses by grounding the model on specific sources of knowledge to supplement the LLM’s internal representation of information. RAG reduces the chances that an LLM will leak sensitive data, or ‘hallucinate’ incorrect or misleading information. RAG also reduces the need for users to continuously train the complete model and update its parameters as circumstances evolve. In this way, RAG can lower the computational and financial costs.
Tokens are the units used by Transformers to process and generate data and the context window is the largest number of tokens an LLM can process at any given time. It is its real-time memory, and it’s akin to what Random-access memory (RAM) is to computer processors. The size of Google’s latest Gemini context window is 10 million tokens, around 7.5 million words, or around 15,000 pages, which is 50 times larger than any other LLM.
Long sequences of text, like financial disclosures, are expensive and hard to model, specifically, the costs of running an LLM have quadratic complexity relative to the sequence length. Transformers suffer greatly from performance degradation when working with sequences longer than what it was trained for. Google Gemini 1.5 has introduced a Mixture-of-Experts (MoE) – multiple LLMs. The principle is, instead of having one large expert model, you assemble a group of smaller expert models specialized in certain regions of the input.
In the context of tagging Financial Disclosures with XBRL, you can create a representation of the taxonomy model, standard structures in financial disclosures (statements, notes, etc.) and the taxonomy structure and semantic labels. The LLM step-change is that similarity is no-longer based on a simple keyword search, but instead on an ontological understanding where similar items are close together in the embedding space.
The embeddings can be used with general models, GPT4, Gemini, Llama to undertake similarity searches across a document and to get a good ‘understanding’ (representation) of a company’s report. This allows the system to make more intelligent decisions across the document. It also enables a more accurate and intuitive understanding of similarity, across languages, regions, and industries.
Looking Forward on AI Tagging
The initial POC using traditional AI approach to NLP was a start, but the results meant that the model would have needed significantly more development. This development effort could be never ending as there are endless possibilities for presenting and reporting financial results.
LLMs give an initial model that understands general language. Using RAG and the advances that tools like Google’s Gemini have made in ‘multiple experts’ promises to provide better results for a smaller development effort.
From the point of view of datasets on which to train such models, the EU has plans to develop the European Single Access Point (ESAP), similar to the US EDGAR system, for both financial disclosures (ESEF) and sustainability (ESRS) reports. This would provide the depth of well-defined reports to provide the training on financial disclosures and XBRL tag history. In the meantime, XII has provided the XBRL Filings website and can be used to retrieve thousands of European reports.
The quality of the data is also improving as companies become more familiar with the requirements of ESEF and XBRL tagging. Taxonomies such as ESEF, being based upon the IASB’s IFRS reference taxonomy, already include data quality checks via XBRL Formulas and Calculation Linkbases. ESEF adds an extensive list of Filing Rules that the submission must also meet to be accepted. In addition, most European countries require the reports to be audited as the reporting entities are listed companies or large private companies for ESRS. The XBRL US Data Quality Committee (DQC) has introduced a proprietary set of rules as a way of improving the quality of US SEC reports.
However, as discussed in earlier articles, the movement towards a ‘digital first’ approach will be the big game changer. Digital first is where companies start with HTML publishing, rather than PDF conversion. This ensures that the underlying structure of the reports is clearer, and the readability of block tags (larger sections of text, tables) will make them much more conducive to AI analysis.
So, we believe that as AI techniques develop and LLMs become more capable, then this will be a more fruitful approach than standard NLP. However, the question still remains, will these systems be totally trustworthy such that a CFO totally trusts his Financial Report tagged using AI techniques, i.e., will they meet the Charlie Hoffman’s ‘objective software’ test, that software will process information in a manner that is as good as a human could have performed that task/process or even better than a human could have performed that task/process (see more here).
One further observation covered in earlier articles, is that financial disclosures contain both semi-structured data (in tables) and unstructured data in text or block tags. Think of the table-based layout of financial statements versus the director’s statements containing key financial highlights. The former are all presented in a slightly different way depending on company type, but all follow the IFRS or local GAAP guidelines. This data comes from highly structured sources, financial consolidation systems. As identified in our earlier posts there is already a trend where financial system software providers incorporate the XBRL into their systems. Tagging the data at this stage or as the tables are generated is much easier. The tagged data can then be passed to ‘digital publishing software’ like Reportl (Friends Studio) or Pomelo to tag the remaining parts of the document. Deploying AI tagging in this way with focus on the unstructured areas would make sense from an effort and accuracy point of view.
Conclusions
In the next few years, we are likely to see a general move to digital-first reporting, with a range of reporting solutions, such as those above, and hence we should see much better results from automatic tagging using AI. tools.
We strongly believe that the use of AI could enable companies and auditors to significantly reduce costs and focus more of their attention on improving the quality of tagged data, rather than manual tagging.
As this article goes to print (digital, of course), we note a stream of new development in LLMs. Way too much to cover and this is not meant to be a natural language processing paper.
However, if you are into AI, like us, look for articles on small language models, less computer resource and ‘bigger bang for buck’; the new faster GPT-4o model from OpenAI; Google unveiling a new “multimodal” AI agent that can answer real-time queries across video, audio and text called Project Astra; Meta also launching its Llama 3 model, with vastly improved capabilities like reasoning.
The authors are Kapil Verma and Martin DeVille of UBPartner
Please send comments, corrections, and any alternative ideas to info@ubpartner.com.